大学时代,我们就已经学过链表了,例如下面的例子struct person
{
int height;
int weight;
struct person *prev, *next;
};
// 查找指定的person是否存在
int person_exists(struct person *head, struct person in_person)
{
struct person *p;
for(p = head->next; p != head; p = p->next)
{
if(p->height == in_person.height && p->weight == in_person.weight)
return 1;
}
return 0;
}
上面的代码定义了struct person这样的链表,通常会实现该链表的插入、删除、查找等操作。现在因为业务需求,又需要struct animal这样的链表,同样,我们也会实现该链表的插入、删除、查找等操作。struct animal
{
int legs;
struct animal *prev, *next;
};
// 查找指定的animal是否存在
int animal_exists(struct animal *head, struct animal in_animal)
{
struct animal *p;
for(p = head->next; p != head; p = p->next)
{
if(p->legs == in_animal.legs)
return 1;
}
return 0;
}
那如果再出现其他的数据类型也需要使用到链表的操作,我们也要为新增的数据类型编写新的链表插入、删除、查找等操作,这样就出现了大量的冗余代码。其实,查找person与anmial是否存在的代码处理逻辑都是一样的,只是数据类型不一样而已。所以为了解决这个问题,linux内核中把与链表有关的操作抽象出来,其他需要使用链表操作的数据类型只要使用内核定义的链表就OK,无需自己再开发与链表的基本操作相关的代码。
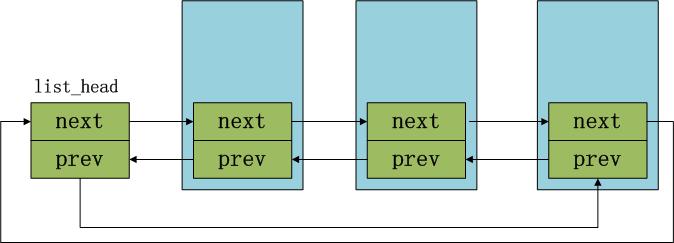
linux内核双向循环链表仅仅使用了一个数据结构struct list_head,即链表的头结点和数据结点都是使用struct list_head表示struct list_head{
struct list_head *next, *prev;
};
让我们看看使用了struct list_head的struct animal是怎样的。下面代码中的INIT_LIST_HEAD、list_add、list_for_each_entry都是linux内核实现的。它的具体实现可以参考include/linux/list.hstruct animal
{
int legs;
struct list_head list;
};
// 初始化链表头结点
struct list_head animal_list;
INIT_LIST_HEAD(&animal_list);
// 初始化struct animal
struct animal animal1;
animal1.legs = 4;
INIT_LIST_HEAD(&animal1.list);
// 将animal1加入链表
list_add(&animal1, &animal_list);
// 加入其它animal到链表
.....
// 遍历 animal_list
struct animal *p_animal;
list_for_each_entry(p_animal, &animal_list, list)
{
printf("legs = %d\n", p_animal->legs);
}
它的内存布局如下: